장단기 메모리(Long Short-Term Memory: LSTM)는 시계열 자료에 많이 사용되는 딥러닝 알고리즘입니다.
LSTM 구동 예시
Gemini와 ChatGPT로 오존 농도를 추정하는 LSTM 코드를 만들었고, 이 코드를 스파이더에서 실행한 화면입니다.
도시대기측정소 한 지점의 기준성 대기오염물질(PM2.5, PM10, SO2, NO2, CO)과 ASOS 기상(풍향, 풍속) 자료만 사용했습니다. 오존을 모델링하기 위해서는 일사량이나 다른 기상정보를 추가할 수도 있지만, 지금은 단순 LSTM 예시 코드를 만들고, 머신러닝 중에서 가장 자주 사용하는 랜덤 포레스트와 비교하기 위해 최대한 간단한 자료만 사용했습니다.

1년 동안의 일평균 농도 추세입니다. 실측값과 모델값 추세가 상당히 일치합니다.

테스트 세트 중에서 1주일 동안의 시간별 추세 그림입니다.

시간과 일평균 자료의 산포도입니다.

모델 성능 결과표입니다. 훈련 세트와 테스트 세트 결과가 모두 양호합니다. Transformer와 CNN-Transformer도 돌려 봤는데 LSTM 결과가 가장 좋았습니다.
LSTM Performance Report: Train vs Test
---------------------------------------------------------------------------------
Metric Train (Hourly) Train (Daily) Test (Hourly) Test (Daily)
MAE 3.1412 0.8307 3.4317 0.8988
RMSE 4.5362 1.0934 4.7000 1.1533
R2 0.9075 0.9891 0.8038 0.9570
IA 0.9747 0.9971 0.9434 0.9877
===============================================
랜덤 포레스트 결과(시계열 방식)
동일한 자료 처리( 24시간의 데이터를 묶어서 다음 1시간을 예측하는 시계열(Sliding Window 방식)에 기반해서 랜덤 포레스트도 수행했습니다. 과거 정보를 포함하므로 머신러닝 모델임에도 불구하고 시계열 특성(추세, 주기성)을 상당 부분 반영할 수 있습니다. LSTM은 시계열 특성을 파악하는 알고리즘이지만 자료 양이 충분하지 않거나 파라미터 튜닝이 어려울 때는 랜덤 포레스트 성능이 좋은 경우가 많습니다.
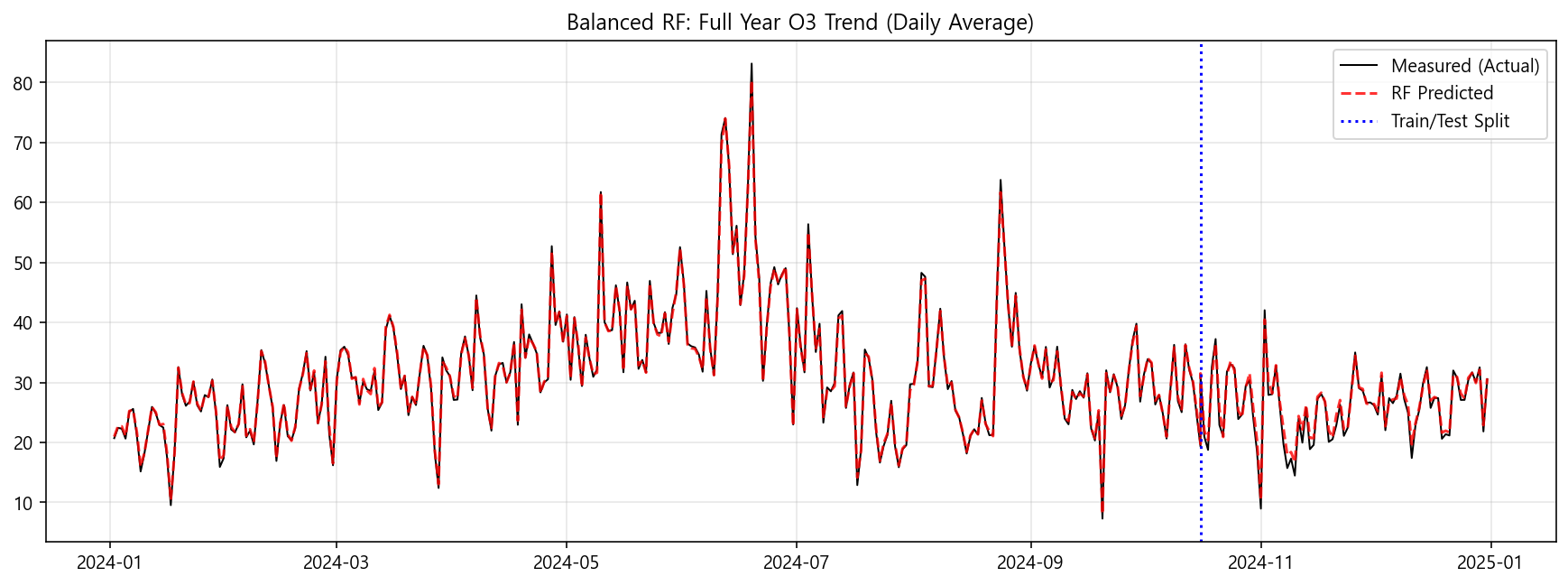

Comprehensive Performance Report: Train vs Test (Balanced RF)
----------------------------------------------------------------------------------
Metric Train (Hourly) Train (Daily) Test (Hourly) Test (Daily)
MAE 1.5008 0.3360 3.3758 0.8292
RMSE 2.3705 0.4644 4.6765 1.0868
R2 0.9747 0.9980 0.8057 0.9618
IA 0.9934 0.9995 0.9445 0.9892
===============================================
랜덤 포레스트 결과(기본 방식)
일반적으로 사용하는 방식은 현재 시점의 독립 변수 자료로 현재 시점의 결과를 추정합니다.
개별 행(다변량)이 독립적인 관측치이며, 각 행 사이의 시간적 순서는 무시됩니다. 데이터를 무작위로 섞어서 학습해도 결과가 크게 달라지지 않습니다.
아래 그림에서 왼쪽의 훈련 세트 기간에는 어느 정도 증감 추세를 맞추지만(고농도/저농도 사례에 대한 성능은 부족), 테스트 세트에서는 성능이 많이 낮아졌습니다.


아래 모델 성능 수치를 보면 확실히 과적합 결과가 나왔습니다. 모델 훈련은 어느 정도 잘 되었는데, 독립적인 자료인 테스트 세트에 대한 결과 수치가 낮습니다. 파라미터 튜닝을 몇 번 시도했는데 결과가 썩 나아지지 않습니다.
주의: 위에서도 언급했듯이 이 기본 모델링은 여러 추가적인 기상자료, lag 변수, 날짜/시간 등을 고려하지 않는 단순 예시입니다. 기본적인 한계가 있지만 모델 조건만 잘 맞으면 충분히 높은 성능을 보일 수 있습니다.
Optimized Performance Report: Train vs Test
---------------------------------------------------------------------------------
Metric Train (Hourly) Train (Daily) Test (Hourly) Test (Daily)
MAE 4.4600 2.9573 6.8471 4.4489
RMSE 6.4759 4.2969 8.7455 5.4101
R2 0.8111 0.8314 0.3202 0.0440
IA 0.9354 0.9399 0.7670 0.7092
===============================================
변수 중요도는 역시 NO2가 가장 높습니다. O3와 NO2 관계는 환경 전공 학생들을 다들 잘 알고 있겠지요?
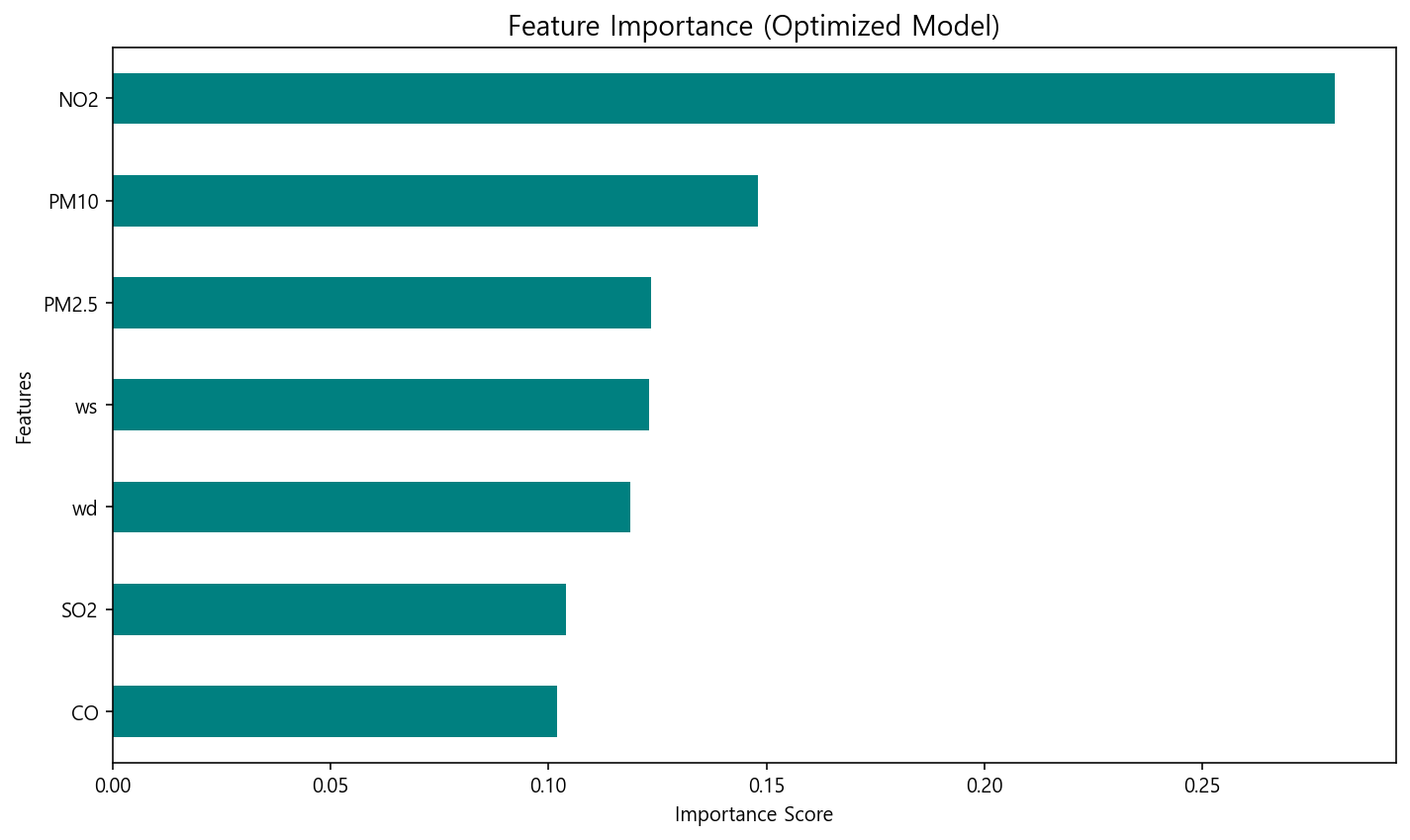
위의 결과를 정리하면,
LSTM식 RF는 "지난 24시간의 기상조건과 다른 오염물질 추세를 반영해서 현재의 특정 오염물질 농도 수준을 추정"하며, 기본 RF는 "현재의 기상조건과 다른 오염물질 농도에 따라 특정 오염물질 농도를 추정"합니다.
기본 RF 결과가 좋지 않으면 LSTM식 RF를 시도할 필요가 있습니다.
'자료처리' 카테고리의 다른 글
| R shiny를 이용한 울산 대기오염 대시보드 작성 (0) | 2026.04.24 |
|---|---|
| R과 파이썬으로 농도가중역궤적(CWT) 그리기 (0) | 2026.01.27 |
| TensorFlow 기반 파이썬 딥러닝 준비 사항 (0) | 2026.01.21 |
| 파이썬 개발환경 스파이더(Spyder) 소개와 벡터형 그림 저장 (0) | 2026.01.19 |
| R 콘솔 언어 변경하기 (0) | 2025.10.03 |




댓글